I found a new benchmark paper from Meituan:AMO-Bench: Large Language Models StillStruggle in High School Math Competitions.
This paper introduces AMO-Bench, a new advanced mathematical reasoning benchmark with 50 original Olympiad-level problems designed to test LLMs. It targets the growing issue that existing math benchmarks(AIME 24, AIME 25) have become too easy for top-tier models, leading to performance saturation.
Key Features of AMO-Bench
- Completely Original Problems
- All 50 problems were human-crafted by math experts and verified to avoid data leakage from existing competitions or online datasets.
- Olympiad-Level Difficulty
- Each problem meets or exceeds the IMO difficulty standards
- Problems were validated by both human experts and LLM difficulty filters.
- Final-Answer Evaluation
- Only the final numeric or symbolic answer is required, enable automatic and scalable grading.
- Human-Annotated Reasoning Paths
- Each problem includes detailed human-written reasoning steps to support future interpretability and prompt engineering research.
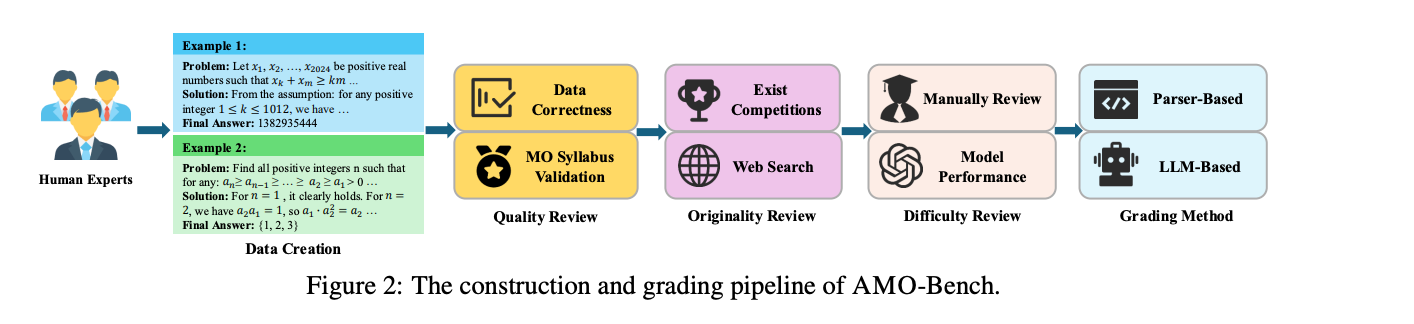
Data Construction Process
The benchmark’s design pipeline includes:
- Data creation by Olympiad-trained experts
- Quality and originality review by multi-expert blind checks and web searches
- Difficulty review ensuring IMO-level rigor and rejecting problems solved easily by top LLMs
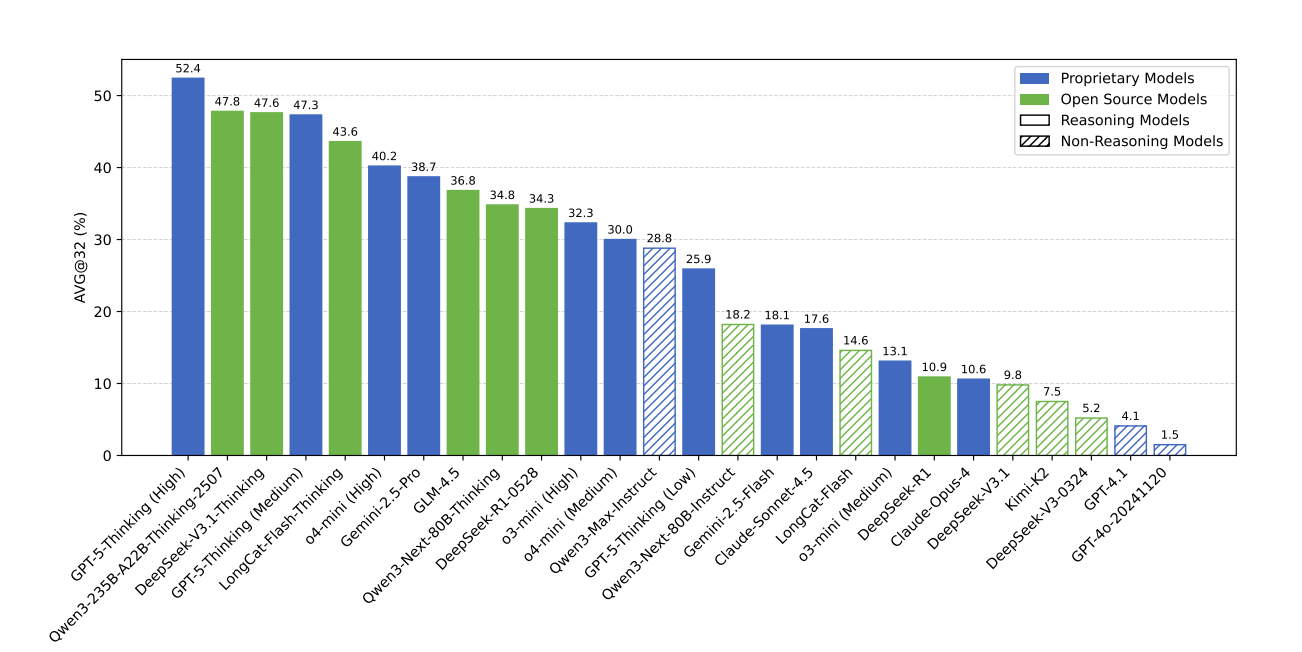
Experimental Findings
Across 26 LLMs, result reveal:
- Top performance: GPT-5-Thinking(High) with 52.4% accuracy
- Most models: Below 40% accuracy
- Even new reasoning models struggle (eg. Gemini-2.5-Pro, DeepSeek-V3.1)
Analysis
- Reasoning efficiency correlates with output length and higher-performing models produces much longer outputs
- linear scaling trend: accuracy improves roughly linearly with log(output length), suggesting test-time scaling still works
- High pass @32(>70%) which indicates that many models can reach correct reasoning paths occasionally but lack consistency.
评论